from itertools import chain from typing importDict import numpy as np import torch import torch.optim as optim from allennlp.data.data_loaders import MultiProcessDataLoader from allennlp.data.samplers import BucketBatchSampler from allennlp.data.vocabulary import Vocabulary from allennlp.models import Model from allennlp.modules.seq2vec_encoders import Seq2VecEncoder, PytorchSeq2VecWrapper from allennlp.modules.text_field_embedders import TextFieldEmbedder, BasicTextFieldEmbedder from allennlp.modules.token_embedders import Embedding from allennlp.nn.util import get_text_field_mask from allennlp.training import GradientDescentTrainer from allennlp.training.metrics import CategoricalAccuracy, F1Measure from allennlp_models.classification.dataset_readers.stanford_sentiment_tree_bank import StanfordSentimentTreeBankDatasetReader
from allennlp.common import JsonDict from allennlp.data import DatasetReader, Instance from allennlp.data.tokenizers.spacy_tokenizer import SpacyTokenizer from allennlp.models import Model from allennlp.predictors import Predictor from overrides import overrides from typing importList
# You need to name your predictor and register so that `allennlp` command can recognize it # Note that you need to use "@Predictor.register", not "@Model.register"! @Predictor.register("sentence_classifier_predictor") classSentenceClassifierPredictor(Predictor): def__init__(self, model: Model, dataset_reader: DatasetReader) -> None: super().__init__(model, dataset_reader) self._tokenizer = dataset_reader._tokenizer or SpacyTokenizer()
@overrides def_json_to_instance(self, json_dict: JsonDict) -> Instance: words = json_dict["words"] # This is a hack - the second argument to text_to_instance is a list of POS tags # that has the same length as words. We don't need it for prediction so # just pass words. returnself._dataset_reader.text_to_instance(words, words)
我们在该任务中只需导入并调用
1 2 3 4 5 6 7 8
from realworldnlp.predictors import SentenceClassifierPredictor
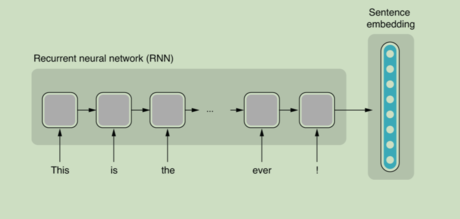
predictor = SentenceClassifierPredictor(model, dataset_reader=reader) logits = predictor.predict('This is the best movie ever!')['logits'] # 任意例句
from flask import Flask, request, jsonify from allennlp.models.archival import load_archive from allennlp.predictors import Predictor from allennlp.data.tokenizers import SpacyTokenizer import torch
from itertools import chain from typing importDict
import numpy as np import torch import torch.optim as optim from allennlp.data import TextFieldTensors from allennlp.data.data_loaders import MultiProcessDataLoader from allennlp.data.samplers import BucketBatchSampler from allennlp.data.vocabulary import Vocabulary from allennlp.models import Model from allennlp.modules.seq2vec_encoders import Seq2VecEncoder, PytorchSeq2VecWrapper from allennlp.modules.text_field_embedders import TextFieldEmbedder, BasicTextFieldEmbedder from allennlp.modules.token_embedders import Embedding from allennlp.nn.util import get_text_field_mask from allennlp.training.metrics import CategoricalAccuracy, F1Measure from allennlp.training import GradientDescentTrainer from allennlp_models.classification.dataset_readers.stanford_sentiment_tree_bank import \ StanfordSentimentTreeBankDatasetReader
from realworldnlp.predictors import SentenceClassifierPredictor
EMBEDDING_DIM = 128 HIDDEN_DIM = 128
# Model in AllenNLP represents a model that is trained. @Model.register("lstm_classifier") classLstmClassifier(Model): def__init__(self, embedder: TextFieldEmbedder, encoder: Seq2VecEncoder, vocab: Vocabulary, positive_label: str = '4') -> None: super().__init__(vocab) # We need the embeddings to convert word IDs to their vector representations self.embedder = embedder
self.encoder = encoder
# After converting a sequence of vectors to a single vector, we feed it into # a fully-connected linear layer to reduce the dimension to the total number of labels. self.linear = torch.nn.Linear(in_features=encoder.get_output_dim(), out_features=vocab.get_vocab_size('labels'))
# Monitor the metrics - we use accuracy, as well as prec, rec, f1 for 4 (very positive) positive_index = vocab.get_token_index(positive_label, namespace='labels') self.accuracy = CategoricalAccuracy() self.f1_measure = F1Measure(positive_index)
# We use the cross entropy loss because this is a classification task. # Note that PyTorch's CrossEntropyLoss combines softmax and log likelihood loss, # which makes it unnecessary to add a separate softmax layer. self.loss_function = torch.nn.CrossEntropyLoss()
# Instances are fed to forward after batching. # Fields are passed through arguments with the same name. defforward(self, tokens: TextFieldTensors, label: torch.Tensor = None) -> torch.Tensor: # In deep NLP, when sequences of tensors in different lengths are batched together, # shorter sequences get padded with zeros to make them equal length. # Masking is the process to ignore extra zeros added by padding mask = get_text_field_mask(tokens)
probs = torch.softmax(logits, dim=-1) # In AllenNLP, the output of forward() is a dictionary. # Your output dictionary must contain a "loss" key for your model to be trained. output = {"logits": logits, "cls_emb": encoder_out, "probs": probs} if label isnotNone: self.accuracy(logits, label) self.f1_measure(logits, label) output["loss"] = self.loss_function(logits, label)
# You can optionally specify the minimum count of tokens/labels. # `min_count={'tokens':3}` here means that any tokens that appear less than three times # will be ignored and not included in the vocabulary. vocab = Vocabulary.from_instances(chain(train_data_loader.iter_instances(), dev_data_loader.iter_instances()), min_count={'tokens': 3}) train_data_loader.index_with(vocab) dev_data_loader.index_with(vocab)
# BasicTextFieldEmbedder takes a dict - we need an embedding just for tokens, # not for labels, which are used as-is as the "answer" of the sentence classification word_embeddings = BasicTextFieldEmbedder({"tokens": token_embedding})
# Seq2VecEncoder is a neural network abstraction that takes a sequence of something # (usually a sequence of embedded word vectors), processes it, and returns a single # vector. Oftentimes this is an RNN-based architecture (e.g., LSTM or GRU), but # AllenNLP also supports CNNs and other simple architectures (for example, # just averaging over the input vectors). encoder = PytorchSeq2VecWrapper( torch.nn.LSTM(EMBEDDING_DIM, HIDDEN_DIM, batch_first=True))
model = LstmClassifier(word_embeddings, encoder, vocab)
predictor = SentenceClassifierPredictor(model, dataset_reader=reader) logits = predictor.predict('This is the best movie ever!')['logits'] label_id = np.argmax(logits)