YOLOv1原理解析
例会讲义, 摘自《YOLO目标检测》
Network Structure
overview
- 逻辑:仅使用一个卷积神经网络来端到端地检测目标(not two-stage)
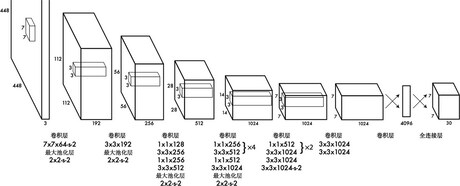
遗风:图像分类网络都会将特征图展平(flatten),得到一个一维特征向量,然后连接全连接层去做预测。(如图)
容易计算从特征图被展平,再到连接4096的全连接层时过程的参数量:$$7×7×1024×4096 + 4096 \approx 2×10^{8}$$
YOLOv1这一缺陷是致命的(后续的改进便是优化该层网络结构)
how to realize detection
综述:将输入图像划分成$7\times 7$的网格,然后在网格上做预测。(DL works on CV because of CNN)
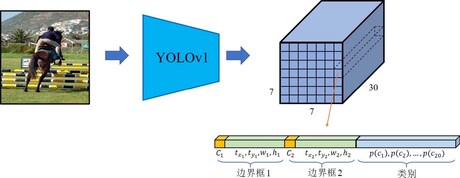
概览YOLO
一张RGB图像输入网络经过一系列的卷积和池化操作后,得到一个经过64倍降采样的 $feature\space map$ (获取高级特征)
将其展平为一个一维的特征向量,再由若干全连接层处理,最后做一些必要的维度转换操作,得到输出张量 $Y \in \mathbb{R}^{7 \times 7 \times 30}$(可以理解为 information map 或者 meta map) (处理特征获取信息)
获取特征
- 将$H \times W$ 的原始图像 处理为 被降采样的 feature map($F \in \mathbb{R}^{H_o \times W_o \times C_o}$).
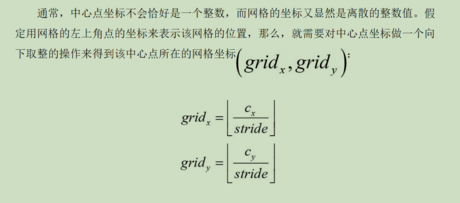
- 存在: (可带大家数一下图中数字)(明确自变量与因变量)(为什么是这些数,炼丹调出来的)$$ H_o = \frac{H}{\text{stride}}, \quad W_o = \frac{W}{\text{stride}} $$
获取信息
为什么要展开
展开实际上是为了方便计算与处理,因为展开后还要还原shape,本质上是从feature map直接获取 information map (具体如何设计获取,我不知道。根据每个grid的特征来预测该grid是否有目标的中心点坐标,以及相应的目标类别。)
我们将输出的information map 看作一个 $7\times7\times\times30$ 的立方体,而 $7\times7$ 可视作将原图像划作成49个网格(grid)

每一个网格对应了一个维度为 30 的向量,该向量包含了 两个预测边界框的置信度与位置参数 以及 目标检测类别的 one-hat 表示 (20是因为使用的是VOC数据集)
其中每一个边界框都包括一个置信度 $C(confidence)$、边界框位置$(t_x, t_y,w, h)$参数,表示边界框的中心点相较于网格左上角点的偏移量$(t_x, t_y)$以及边界框的宽和高$(w ,h)$
因此,我们可以使用 $5B+N_c$ 来计算输出张量的通道数该是多少
、、、、其实YOLOv1的这一检测理念也是从Faster R-CNN中的区域候选网络 (region proposal network,RPN) 继承来的,只不过,Faster R-CNN只用于确定每个网格里是否有目标,不关心目标类别,而YOLOv1则进一步将目标分类也整合进来,使得定位和分类一步到位,从而进一步发展了“anchor-based”的思想。
recap

Detection Principle
边界框
参数$(C, t_x, t_y,w, h)$ 的学习
逻辑概览
YOLOv1是通过检测图像中的目标中心点来实现检测目标,即只有包含目标中心点的网格才会被认为是有物体的。
- $Pr(objectness) = 1$ 代表此网格有物体
- $Pr(objectness) = 0$ 代表此网格无物体
物体在哪个网格,就由该网格去拟合(学习)边界框。
- 该网格内所要预测的边界框,其置信度会尽可能接近1。
- 有物体的网格会被标记为正样本候选区域
- 在训练过程中,训练的正样本(positive sample)只会从此网格处的预测中得到,而其他区域的预测都是该目标的负样本(置信度接近0)。

目标中心点坐标
类似于残差思想,在每个grid的 baseline 上,学习相对于所在网格的偏移量(容易学习。边界框,目标点与所在网格联系密切)

相对偏移量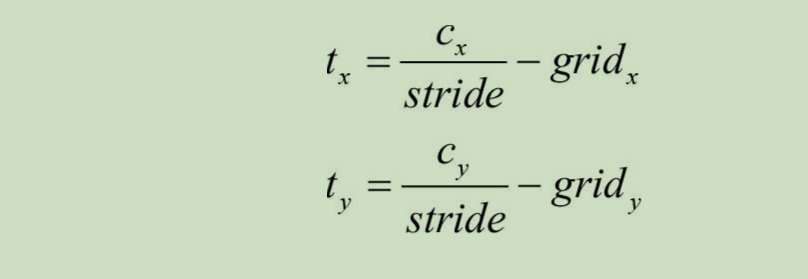
视作训练标签(容易学习)
图示:
边界框的确定:宽与高
我们当然可以直接将目标的真实边界框的宽和高作为学习标签。不过一般进行normalization会更好,也会避免一些问题的发生(我不知道)$$ \bar{w} = \frac{w}{W}
\space\space\space \bar{h} = \frac{h}{H} $$
置信度的学习(范式:二元对立 —> 概率表示)(one-stage 的关键)

如何给置信度的标签赋值呢?一个很简单的想法是,将有目标中心点的网格处的边界框置信度的学习标签设置为1,反之为0,这是一个典型的“二分类”思想,正如Faster-RCNN中的RPN所做的那样。
YOLOv1希望边界框的置信度能表征所预测的边界框的定位精度。因为边界框不仅要表征有无物体,它自身也要去定位物体,所以定位得是否准确同样是至关重要的。而对于边界框的定位精度,通常使用交并比(intersection of union,IoU)来衡量。
$IoU$: 分别计算出两个矩形框的交集(intersection)和并集(union),它们的比值即为IoU。显然,IoU是一个0~1的数,且IoU越接近1,表明两个矩形框的重合度越高。
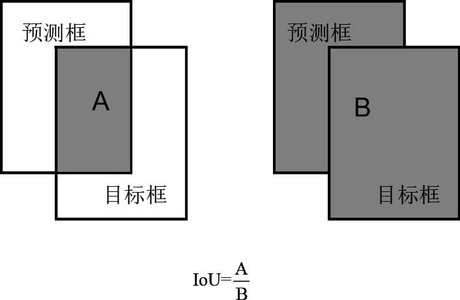
既如此,不妨直接将 $IuO$ 作为置信度的学习标签 😋😋😋
置信度的训练
只需关注那些有目标中心点的网格,即正样本候选区域
仅保留$IoU$ 较大的预测框,让其拟合(学习)目标框, 对于其他预测框将其置信度标签改为0,视作负样本, 和其他网格的预测框一样, 仅计算一次$RoU$ , 不在参与后续的参数拟合(学习)
可以看到,一个正样本的标记是由预测本身决定的,即我们是直接构建预测框与目标框之间的关联,而没有借助某种先验。
后之视今,会发现YOLOv1一共蕴含了后来被着重发展的3个技术点:(我不知道,我抄的)
1. 不使用先验框(anchor box)的anchor-free技术。 (关于先验,可以学习classification中朴素贝叶斯)
2. 将IoU引入类别置信度中的IoU-aware技术
3. 动态标签分配(dynamic label assignment)技术。
分类(类别置信度)
同边界框的学习一样,类别的学习也只考虑正样本网格,而不考虑其他不包含目标中心点的网格。
对于one-hot格式的类别学习,通常会使用$Softmax$函数来处理网络的类别预测,得到每个类别的置信度,再配合交叉熵(cross entropy)函数去计算类别损失
***而YOLOv1使用线性函数输出类别置信度预测,并用$L2$(有关范数,可以理解为最小二乘法)损失来计算每个类别的损失
but this time it did not continue the myth 🙊🙊🙊
YOLOv1预测的类别置信度可能会是一个负数,同样,对于边界框的置信度和位置参数,YOLOv1也是采用线性函数来输出的 (后续改进点)
summary


Loss Function
问题就来到了简单的最小二乘法(线性拟合) (不过是高维形式上) 🤗🤗🤗
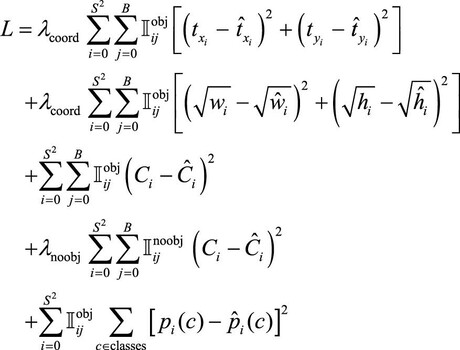
小问题:为什么负样本的置信度也要参与loss的计算 (万能黑箱)
前向推理
对于训练好的YOLOv1,输出的$Y \in \mathbb{R}^{7 \times 7 \times 30}$ (表现如图),需要进行筛选
1. 计算所有预测的边界框的得分
得分score 定义为该边界框的置信度 $C$ 与类别的最高置信度(20个概率的最大值)的乘积
2.得分阈值筛选
设定一个阈值去滤除那些得分低的边界框。(数值表现就是设置为零)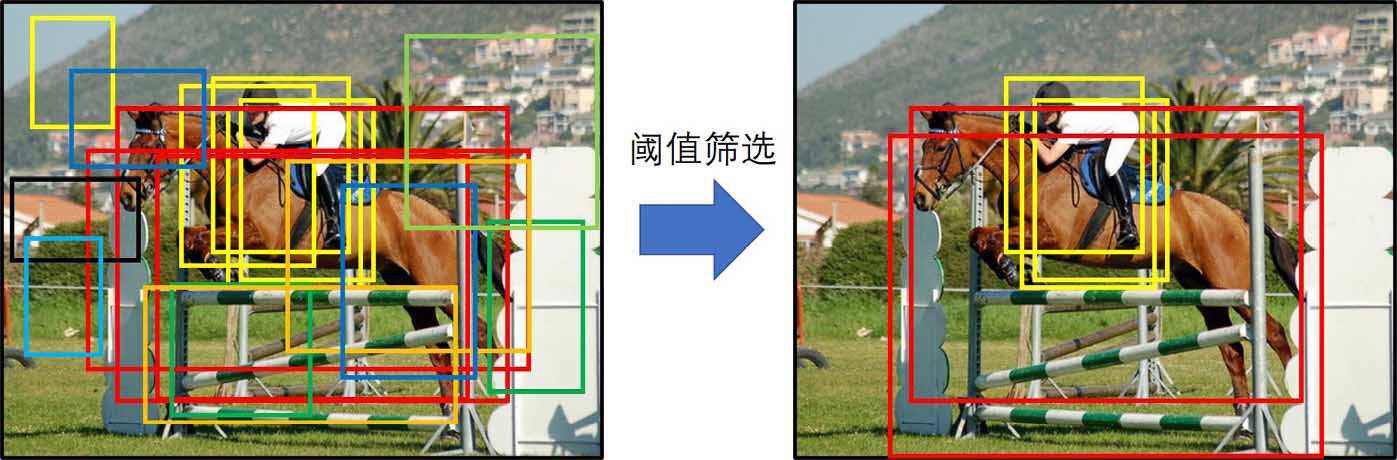
3.计算边界框
计算余下的边界框的中心点坐标以及宽和高。
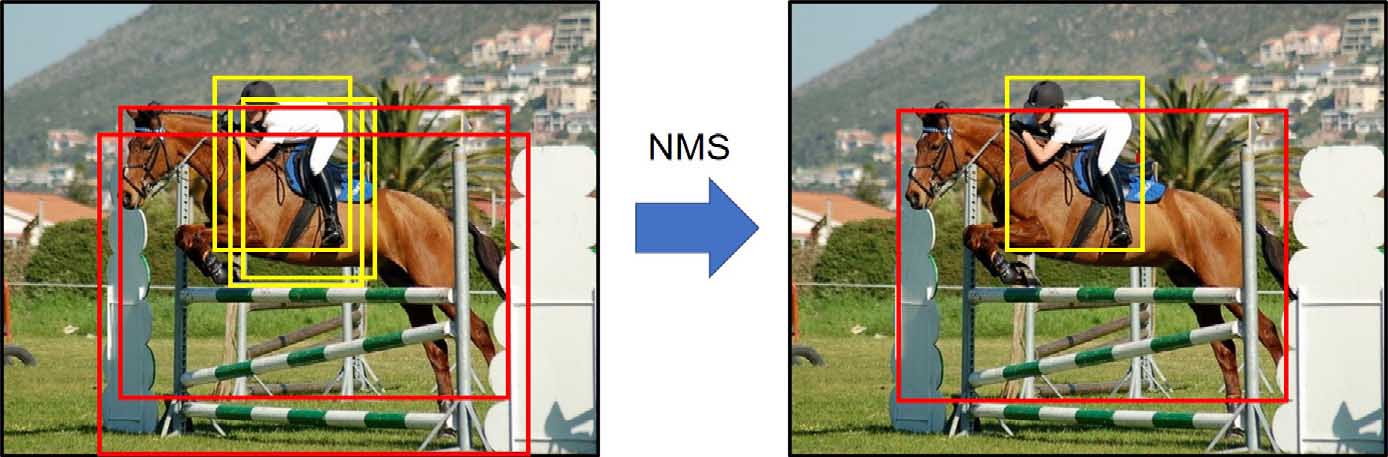
4.使用非极大值抑制(NMS)进行第二次筛选
非极大值抑制(non-maximal suppression,NMS)
非极大值抑制的思想很简单,对于某一类别目标的所有边界框,
先挑选出得分最高的边界框,
再依次计算其他边界框与这个得分最高的边界框的IoU,
超过设定的IoU阈值的边界框则被认为是重复检测,将其剔除。(数值表现就是设置为零)
对所有类别的边界框都进行上述操作,直到无边界框可剔除为止