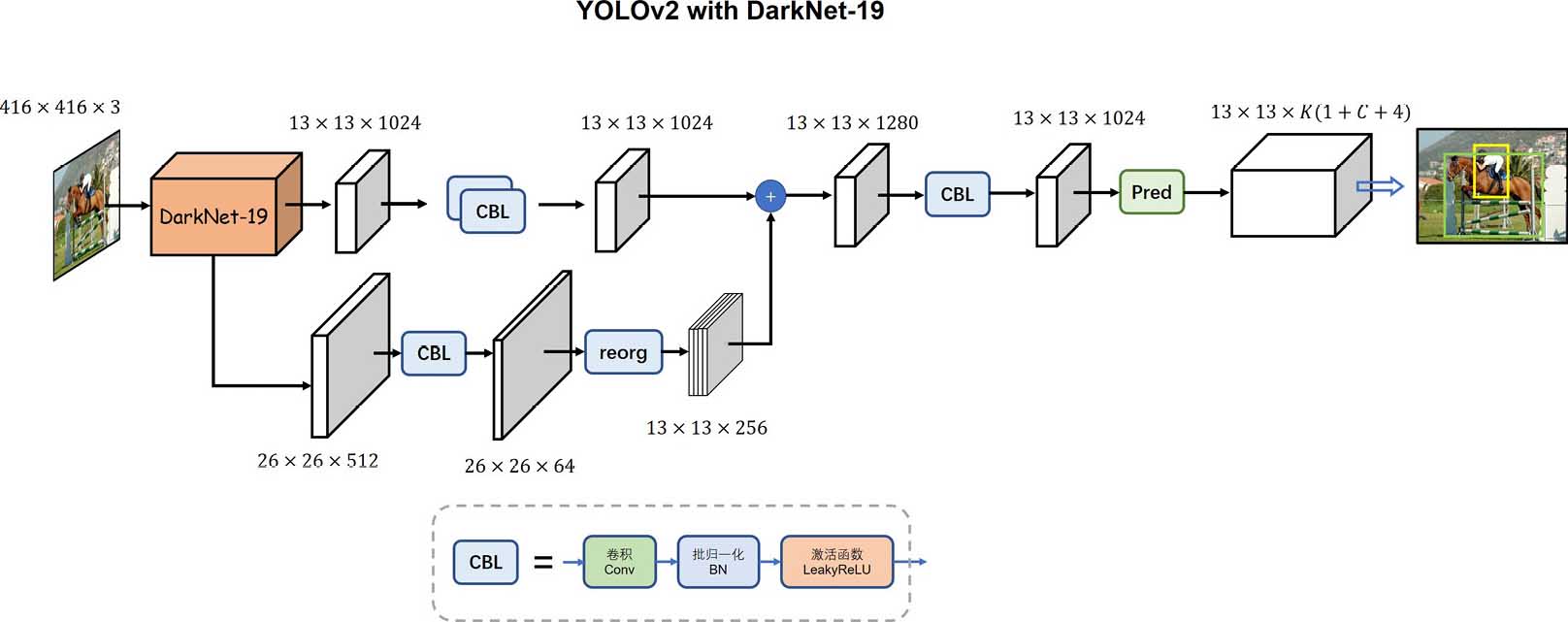
YOLOv2框架解析
~~测试测试
例会讲义, 摘自《YOLO目标检测》
overview
- 使用新的网络结构
- 引入由 Faster R-CNN 工作提出的先验框机制
- 提出基于k均值聚类算法的先验框聚类算法
- 采用新的边界框回归方法
- …………
~ 优化详解
引入批量归一化(BN)层
关于BN ,参考:[[Batch Normalization Layer]]
‘’卷积三件套‘’
高分辨率主干网络
预备知识:预训练(pretrain),微调(fine-tune)
v1中:先基于GoogLeNet的网络结构设计了合适的主干网络,并将其放到ImageNet数据集上进行一次预训练,随后,再将这一预训练的权重作为YOLOv1的主干网络的初始参数
问题:ImageNet 中 图像大小为 $224 \times 224$, 而训练的 voc 中大小为 $448 \times 448$
也就是原来的预训练后的参数不太好,会忽略很多细节特征
解决方案: 微调: 二次预训练 ,再使用 $448\times448$ 稍微训练几次
不过,后来被时代抛弃了, 大家可以想想为什么
先验框机制简介
(抄的)
先验框的意思其实就是在每个网格处都固定放置一些大小不同的边界框,通常情况下,所有网格处所放置的先验框都是相同的,以便后续的处理。
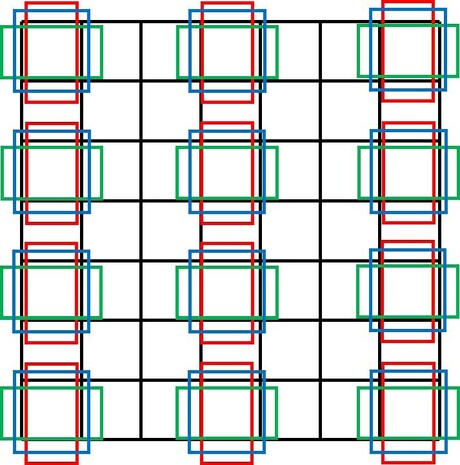
在$RPN (Faster R-CNN)$中,其目的是希望通过预设不同尺寸的先验框来帮助$RPN$更好地定位有物体的区域,从而生成更高质量的感兴趣区域$(region of interest,RoI)$,以提升$RPN$的召回率。事实上,$RPN$的检测思想其实和$YOLOv1$是相似的,都是“逐网格找物体”,区别在于,$RPN$只是找哪些网格有物体(只定位物体),不关注物体的类别,因为分类的任务属于第二阶段;而$YOLOv1$则是“既找也分类”,即找到物体的时候,也把它的类别确定下来。
每个网格都预先被放置了 $K$ 个具有不同尺寸和不同宽高比的先验框(这些尺寸和大小依赖人工设计)。在推理阶段, $Faster R-CNN的RPN$ 会为每一个先验框预测若干偏移量,包括中心点的偏移量、宽和高的偏移量,并用这些偏移量去调整每一个先验框,得到最终的边界框。由此可见,先验框的本质是提供边界框的尺寸先验,使用网络预测出来的偏移量在这些先验值上进行调整,从而得到最终的边界框尺寸。后来,使用先验框的目标检测网络被统一称为$“anchor\space \space box\space \space based”$方法,简称$“anchor-based”$方法。
既然有$anchor-based$,那么自然也会有 $anchor-free$,也就是不使用先验框的目标检测器。事实上,$YOLOv1$ 就是一种$anchor-free$ 检测器
- 难点:怎么设计先验框的参数 (不过我们直接使用别人研究好的就行了 😋😋😋)
全卷积网络与先验框机制
我们提到了全连接层的弊端 见 [[YOLO v1]]
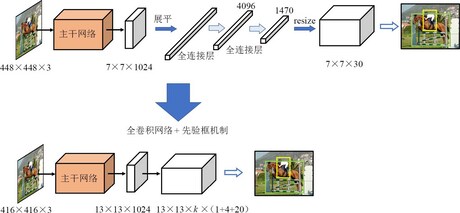
在推理阶段,网络只需要学习能够将先验框映射到目标框的尺寸的偏移量,无须再学习整个目标框的尺寸信息,这使得训练变得更加容易。
v1中每个网格只会预测1个类别的物体, 因为类别置信度是共享的
训练策略:依旧是从 $K$ 个预测的边界框中选择出与目标框的 $IoU$ 最大的边界框作为正样本,其表示有无物体的置信度标签还是最大的 $IoU$ ,其余的边界框则是负样本。
这部分是 可以检测更多物体的关键
使用新的主干网络
自研 “DarkNet-19”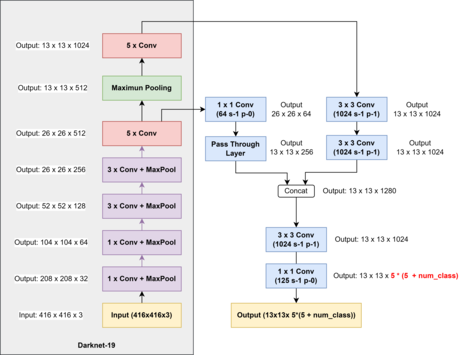
基于k均值聚类算法的先验框聚类
(我没有深入了解过)
核心:对于先验框参数的去人工化, 可以自动地从数据中获得合适的边界框尺寸
- 从VOC数据集中的所有边界框中聚类出 $K$ 个先验框,
- 聚类的目标是数据集中所有边界框的宽和高,与类别无关。
- 为了能够实现这样的聚类,使用IoU作为聚类的衡量指标
- 从A数据集聚类出的先验框可能不适用于B数据集
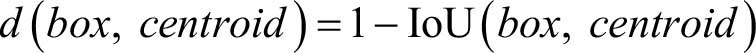
训练设计:
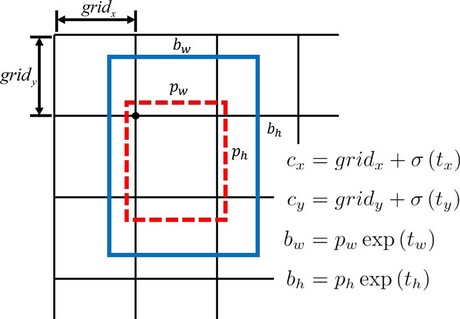
- 对于每一个边界框,YOLO仍旧去学习中心点偏移量 $t_x , t_y$
- 我们知道,这个中心点偏移量是0~1范围内的数
- v1中直接使用线性函数输出,模型很有可能会输出数值极大的中心点偏移量
- 改进:使用Sigmoid函数将网络输出的中心点偏移量映射到0~1
- 利用先验框,便不再学习目标框的宽高 ($location\space\space prediction$)
设某个先验框的宽和高分别是 $P_w, P_h$, 模型输出的宽与高的偏移量分别是 $t_w, t_h$
可使用以下公式计算边界框的中心点坐标 $(c_x, c_y)$ 和 宽与高 $b_w, b_h$
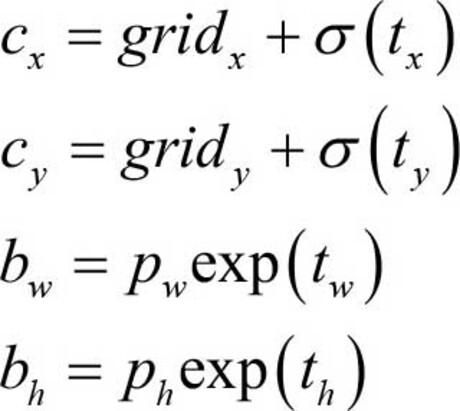
YOLOv2的先验框尺寸都是相对于网格尺度的,而非相对于输入图像,所以求解出来的数值也是相对于网格的。
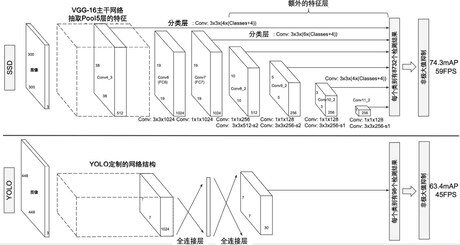
融合高分辨率特征图
借鉴于SSD
- 在SSD工作中,检测是在多张特征图上进行的。
- 不同的特征图的分辨率不同,
- 越是浅层的特征图,
- 越被较少地做降采样处理,
- 因而分辨率就越高,
- 所划分的网格就越精细,
- 这显然有助于去提取更多的细节信息。
对最后输出的feature map 之前的feature map 在进行一次特殊的特征提取(通道翻四倍,信息量不变)
将这两个 feature map 进行通道维度上的拼接(融合特征)
YOLOv2 的 特殊提取 (我想说的就是没有想象的简单)
- 先使用1* 1 卷积 压缩通道8倍(512–> 64)
- 再进行特殊的降采样操作使其变为特征图
- ………………
这里的特殊的降采样操作并不是常用的步长为2的池化或步长为2的卷积操作,而是***reorg
不丢失信息的降采样操作:reorg
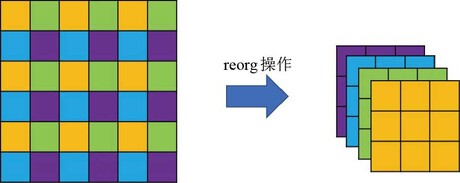
其空间尺寸会减半,而通道数则扩充至原来的4倍,因此,这种特殊降采样操作的好处就在于,降低分辨率的同时未丢失任何细节信息,即信息总量保持不变。
多尺度训练策略
图像处理操作:图像金字塔 (数据增强)

在越大的图像中,其外观越清晰,所包含的信息也就越丰富
其他小尺寸的图像中,细节纹理也相对变少
图像金字塔可以丰富各种尺度的物体数量。
由于数据集中的数据是固定的,因此各种大小的物体的数量也就固定了,但多尺度训练技巧可以通过将每张图像缩放到不同大小,使得其中的物体大小也随之变化,从而丰富了数据集各类尺度的物体,很多时候,数据层面的“丰富”都能够直接有效地提升算法的性能。
每迭代 10次,就从320、352、384、416、448、480、512、544、576、608中选择一个新的图像尺寸用作后续10次训练的图像尺寸。
这些尺寸都是32的整数倍,因为网络的最大降采样倍数就是32
多尺度训练是常用的提升模型性能的技巧之一
使用了多尺度训练,且全卷积网络的结构可以处理任意大小的图像,那么YOLO 就可以使用不同尺度的图像去测试性能。
summary